返利清算系统设计
工作时接触了半年多的返利业务,深入了解之后发现面临的不仅仅是数据量大,也有一些复杂业务场景,这可能就是 toB 业务的通病吧。
记录下一些关于模块划分和操作大量数据的心得体会,其中部分系统和业务名词经过脱敏处理。
业务整体框架h2
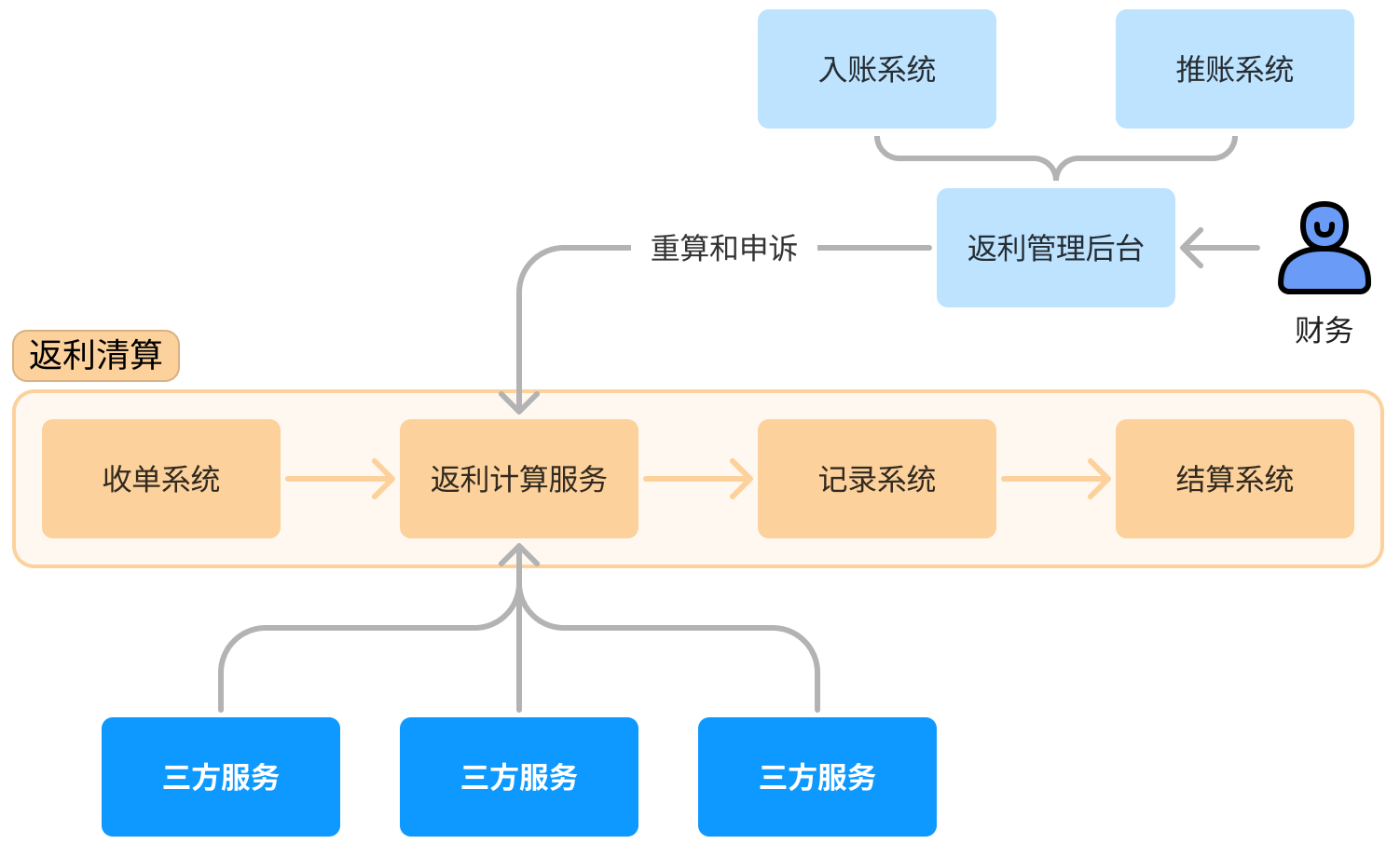
业务分为返利清算和返利结算 下面罗列我所负责的返利清算部分所涉及的相关系统设计
收单系统h2
主要负责收集来自各不同的渠道的订单数据(线上不同商城、线下)。由于订单系统的演变,部分渠道的数据库字段多达 30 多个,看上去很头疼。所以收单系统主要工作就是裁剪那些不需要的字段,同时收拢各个渠道数据,方便后续计算服务。
收集第三方数据分两种模式,一种是数据方推送数据(消息)另一种就是通过定时任务轮询从数据源拉数据回来。发消息的方式可以省下我们一些开发量,但是对于消息丢失或系统重启等情况产生的数据不一致调试起来是很头疼的。
考虑到所有的订单数据都在各订单中心持久化保存,收单系统采用每分钟的定时任务去聚合订单数据,把时间间隔拆分为分钟级可以减少单次同步数据量过大的问题。
返利计算服务h2
返利计算服务作为整个清算流程中最重要的一环,最初的设计目标是为了在保证计算性能的前提下,做到对于各种返利类型的可扩展性。
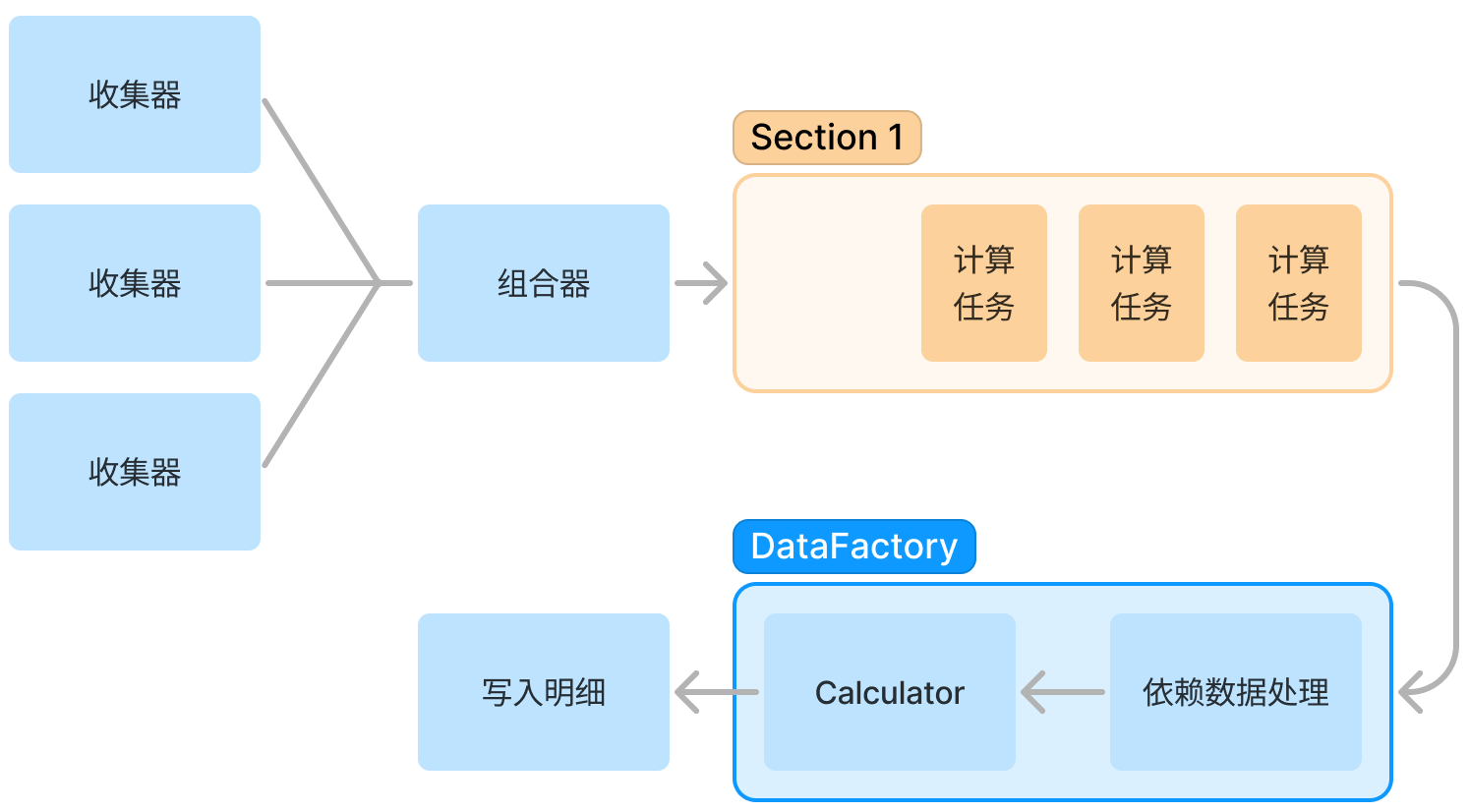
收集器h3
- 确定收集哪些类型的订单,常用的就是妥投和退款
- 部分特殊返利会收集其他月份的历史妥投数据
- 申诉订单会使用到申诉数据
组合器h3
单次返利计算会使用到多个收集器,组合器就是负责组织启动这些收集器。
此时将收集到的订单数据分批放入消息队列中,避免全量数据对内存的压力。
计算器h3
通过消息队列出队顺序调用需要使用的计算器,调用计算器之前需要获取 SKU 配置、政策配置等三方数据。
计算器中就是当前返利类型的所有业务逻辑,是否计算返利、按什么返点比例计算返利、是否满足考核标准等等。
依赖接口的封装h3
为每个第三方 Dubbo 接口封装一个 Adapter 简化调用,下面是一个 Adapter 的伪代码。
@DubboReference()
private ThirdService thirdService;
public List<String> getEventIds(Request request) {
Result<Response> result = thirdService.method(request);
if(result.getCode() != 0) {
throw new RuntimeException(result.getMessage());
}
return result.getData();
}
计算服务通过以上的设计,实现了横向扩展,如果当月有大量计算任务时,只需要扩容相关机器提高批量处理的能力。
通过对于依赖接口的封装降低了第三方接口因不确定导致的系统健壮性问题。
由于实验性的采用了 TiDB 替换了 MySQL 减少了一些分表带来的复杂度,可以不在业务场景上做分库分表,所有的工作都由数据库层完成。
记录系统h2
记录服务主要用于记录每条订单返利的明细。
当返利后台触发撤回操作时需要清空当前发放流程的所有返利明细。写入大量明细通过限制调用方单次写入的 List 大小。平均单个返利类型的明细记录有几百万条,所以写入有压力,删除也有压力。
采用 limit 查询满足条件的主键 ID,再通过 delete 语句删除这些记录。
-
考虑到直接使用 delete 删除大量数据会导致相关索引的大量更新,这个更新锁表时间会很长,期间会影响线上业务
-
并且由于数据库的标记删除,会产生大量存储碎片,可能会导致页分裂
结算系统h2
结算系统就是将所有的返利明细汇总并提供输出接口。
使用 completableFuture 接口,按照天拆分单月返利明细,并发的计算汇总。
将明细和结算拆分开主要考虑到,当订单计算完明细返利之后,还需要财务审核,如果出现审核不通过将不予发放返利。也在结算系统中提供一些结算账单的能力,方便入账和对账。
项目总结h2
相比较纯技术来说,做业务可能没有那么激动人心。但是看着自己解决一个实际的业务难题,合理的对不同职责进行系统拆分,通过财务验收成功上线的时候也是无比开心的。
对于计算服务为了方便不同返利类型的接入也做了很多可扩展和高性能方面的尝试,算是完美达到了当时系统的设计目标了。并且实验性的采用了 TiDB 为我们省去了很多分表的麻烦。
由于篇幅的原因,省略介绍了一些简单的三方配置服务、政策服务等。这里是做一个阶段性记录,在软件的生命周期中项目的架构是随业务目标不断演进的。并且随着之后接触的东西多了,也会觉得现在的设计哪哪不太好呢 hh。